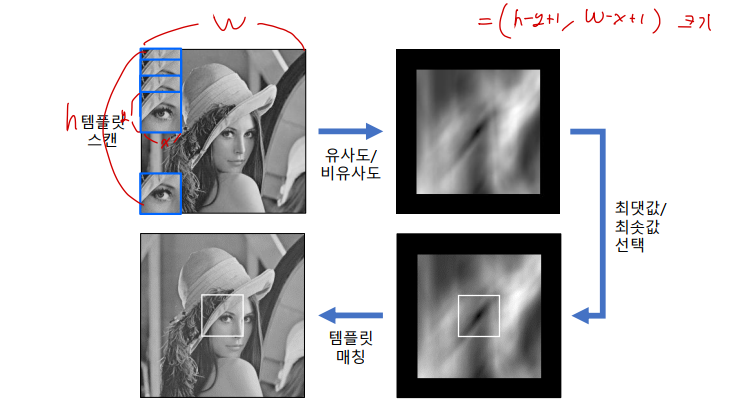
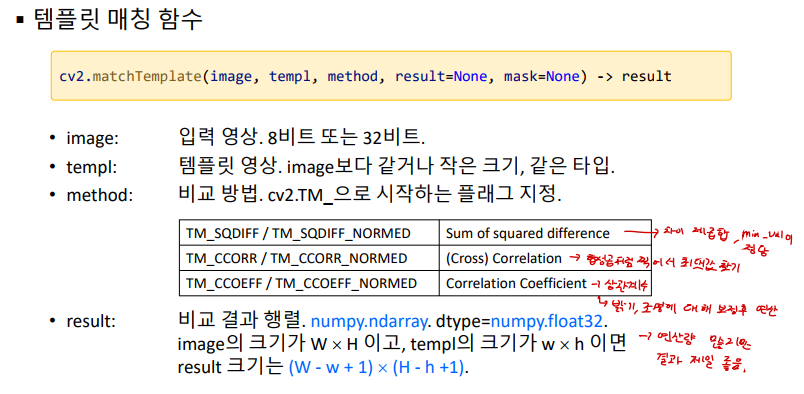
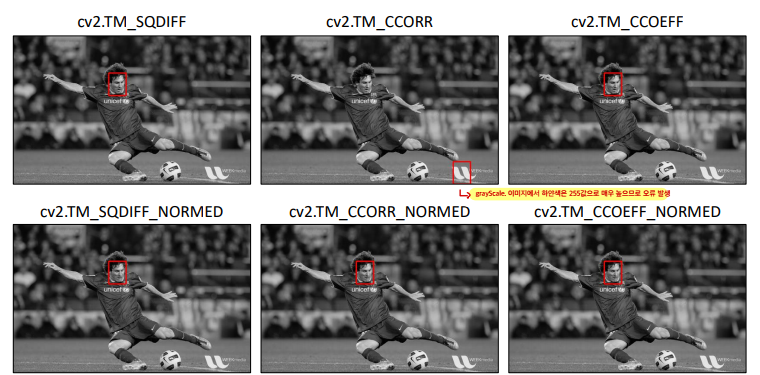
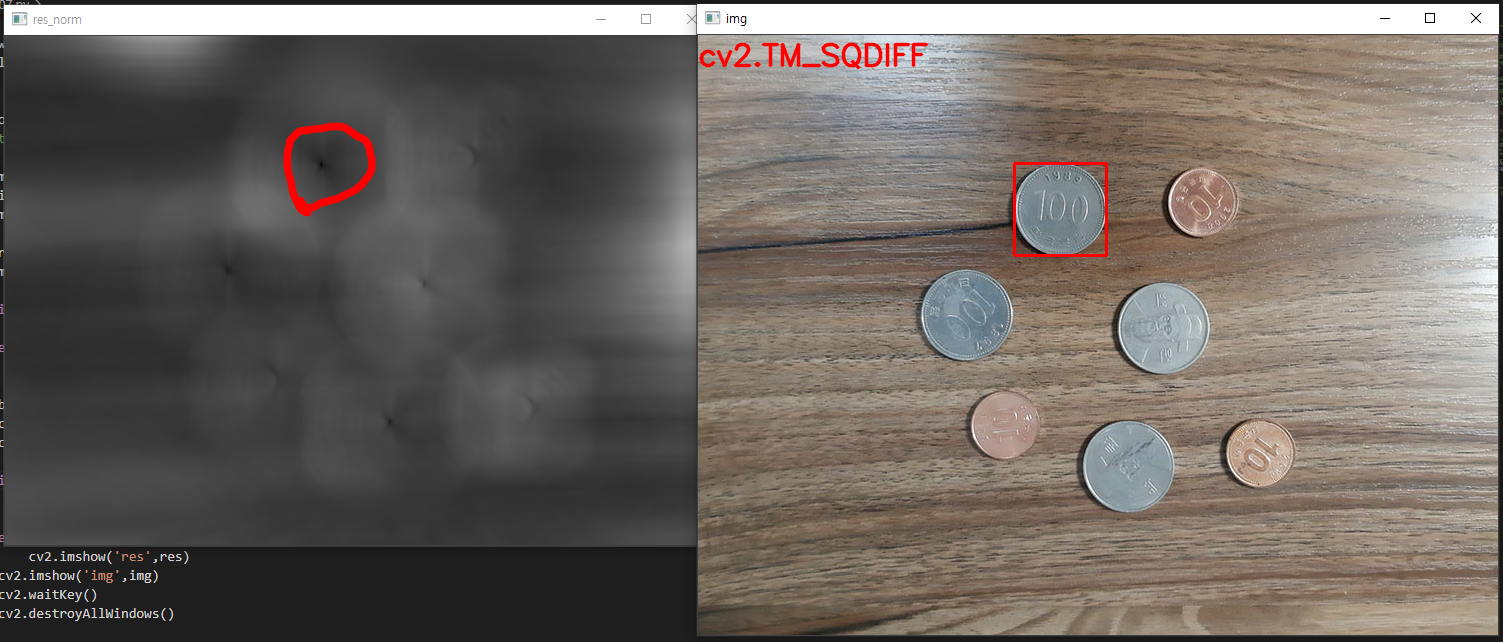
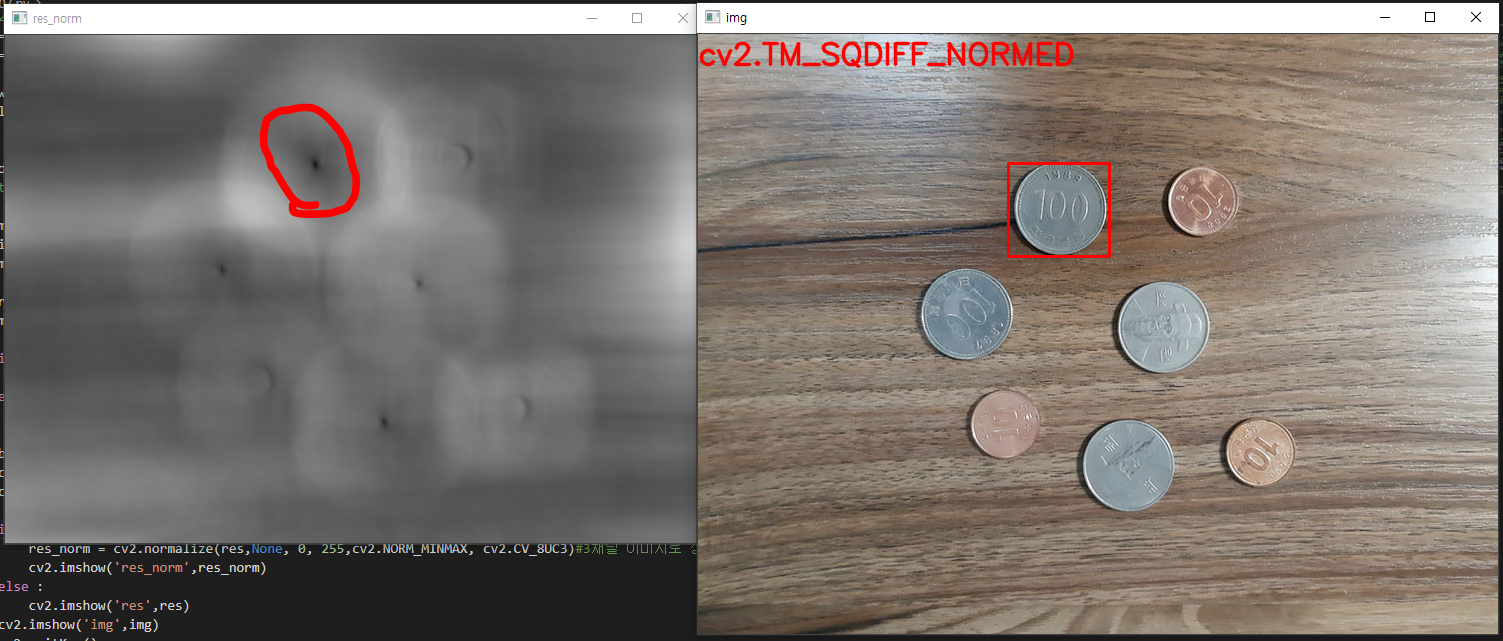
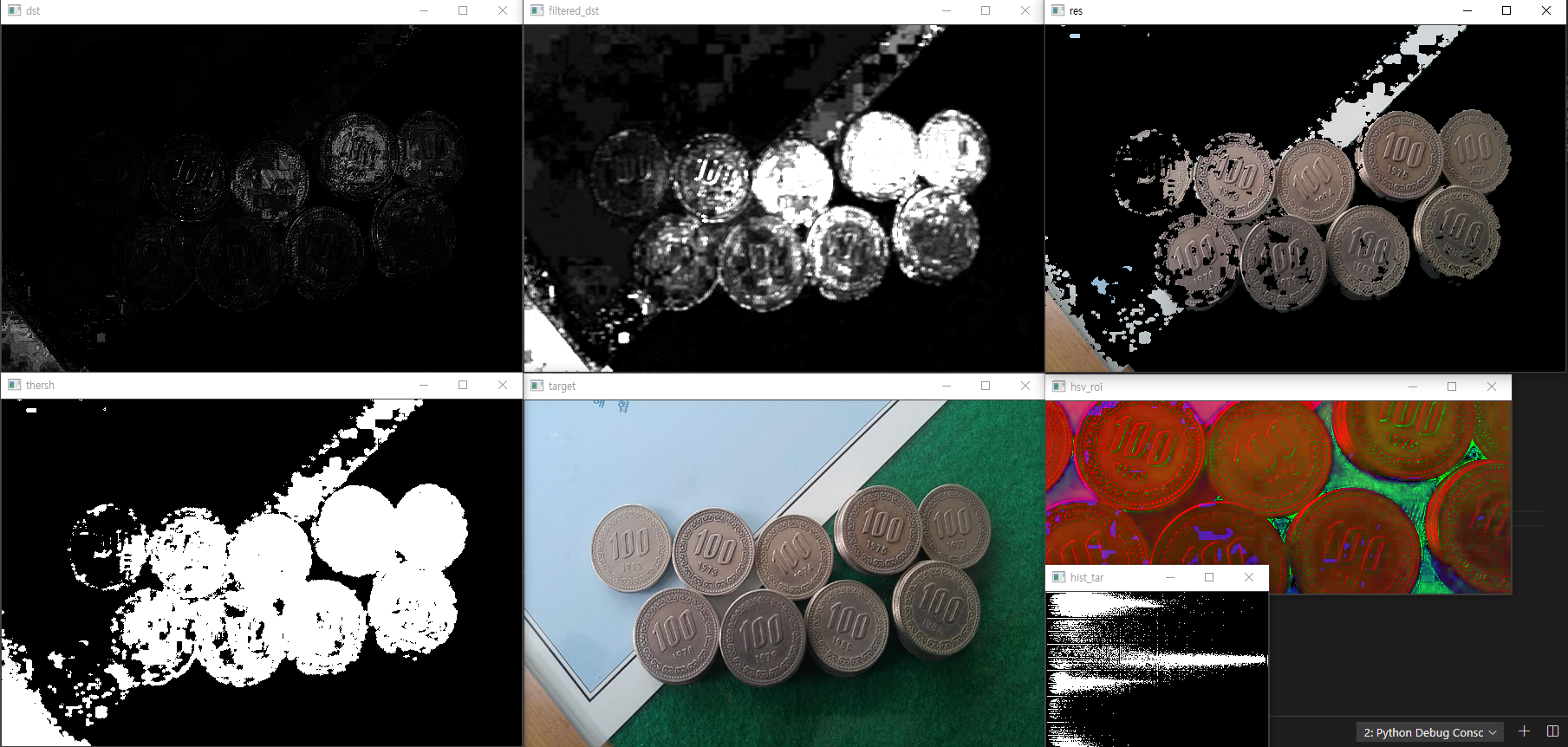
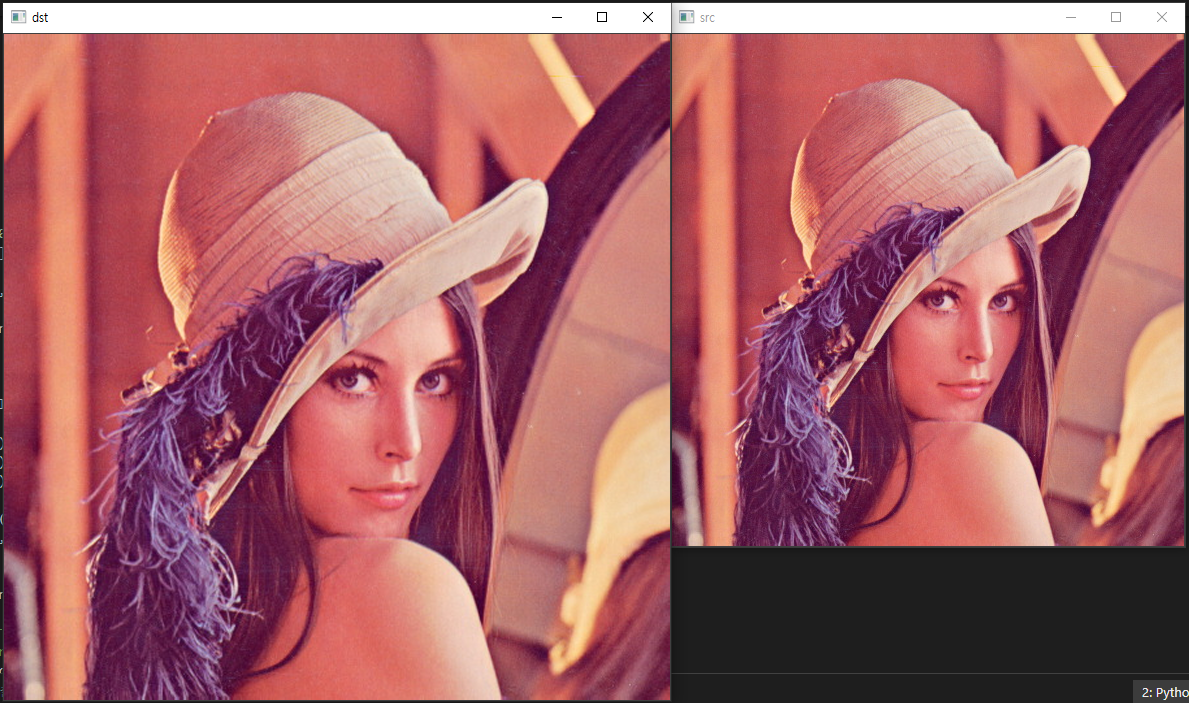
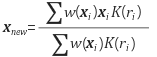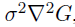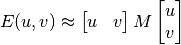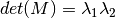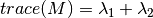영상에서 물체를 추적하고자 할 때, 보통 가장 먼저 떠오르는게 mean-shift 방법일 것이다. 하지만 막상 mean-shift를 이용하여 영상 추적을 하려면 실제 어떻게 해야 하는지 막막한 경우가 많다. 가장 기본적인 방법임에도 불구하고 처음에는 헤매기 쉽다 (저도 그랬습니다 ^^).
1. Mean Shift 란?
시력이 매우 나쁜 사람을 산에다가 던져놓고 산 정상을 찾아오라고 하면 어떻게 될까? 당연히 눈이 보이는 한도 내에서는 가장 높은 쪽으로 걸음을 옮길 것이고, 이렇게 가다보면 산 정상에 다다를 수 있을 것이다. 이러한 탐색 방법을 힐 클라임(Hill Climb) 탐색 방법이라고 부르는데, Mean Shift도 Hill Climb 탐색 방법의 일종이다.
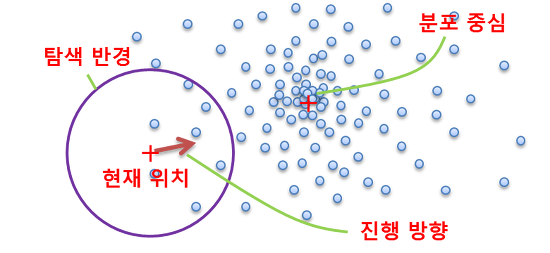
Mean Shift는 어떤 데이터 분포의 peak 또는 무게중심을 찾는 한 방법으로서, 현재 자신의 주변에서 가장 데이터가 밀집된 방향으로 이동한다. 그러다 보면 언젠가는 분포 중심을 찾을 수 있을 거라는 방법이다.
예를 들어, 2차원 평면상에 데이터들이 분포되어 있는데 Mean Shift를 이용하여 이 데이터들이 가장 밀집된 피크(peak) 점을 찾는다고 하자. Mean Shift의 탐색반경을 r이라 했을 때, Mean Shift 알고리즘은 다음과 같다.
현재 위치에서 반경 r 이내에 들어오는 데이터들을 구한다: (x1,y1), (x2,y2), ..., (xn,yn)
이들의 무게중심의 좌표 (∑xi/n, ∑yi/n)로 현재 위치를 이동시킨다.
1~2 과정을 위치변화가 거의 없을 때까지, 즉 수렴할 때까지 반복한다.
Mean Shift란 용어는 평균(mean)을 따라 이동(shift)시킨다는 뜻이다. Shift란 용어는 어떤 것이 현재 상태 그대로 위치만 변할 때 사용된다. 마이클 잭슨의 빌리지인~ 춤을 생각하기 바란다. 여기서는 크기가 고정된 탐색 윈도우를 이동시킨다는 의미이다.
2. Mean Shift 에 대해 좀 더 알아보기
앞서, Mean Shift는 Hill Climb 탐색 방법의 일종이라고 했는데, 비슷한 뜻으로 gradient descent search, blind search, greedy search 등이 있다. 이러한 류의 탐색 방법은 효과적이기는 하지만 local minimum에 빠지기 쉽다는 문제점이 있다. 예를 들어 앞의 산의 정상을 찾는 문제에서 던져진 사람은 바로 옆에 높은 산이 있더라도 처음 출발한 산의 정상만을 찾게 될 것이다. 만일 처음에 매우 완만한 구릉에서 출발했다면 그 구릉 꼭대기에서 멈춰버릴 것이고 그 옆의 진짜 높은 산 정상은 가지 못할 것이다.
Mean Shift와 같은 Hill Climb 방식은 global minimum을 찾지 못하며, 초기위치(출발위치)에 따라서 최종적으로 수렴하는 위치가 달라질 수 있다. 초기 위치는 문제에 따라 미리 주어지거나, 아니면 무작위로 임의의 위치에서 시작하거나, 혹은 전체 데이터의 평균 위치에서 출발하는 등의 방법이 있을 수 있다.
Mean Shift에서는 기본적으로 주변의 지역적인(local) 상황만 보고 진행방향을 결정하기 때문에, Mean Shift를 적용하기 위해서는 먼저 탐색반경(search radius)의 설정이 필요하다. 탐색반경을 너무 크게 잡으면 정확한 피크(peak) 위치를 찾지 못하게 되며, 반대로 너무 작게 잡으면 local minimum에 빠지기 쉬워진다.
Mean Shift의 가장 큰 단점 중의 하나는 탐색 윈도우(탐색 반경)의 크기를 정하는 것이 쉽지 않다는 것이다. 특히 영상 추적의 경우 대상 물체의 크기, 형태 변화에 따라 탐색 윈도우의 크기나 형태를 적절히 변경해 주어야 하는데 이게 적절히 변경되지 않으면 추적 성능에 많은 영향을 끼치게 된다.
Mean Shift는 물체추적(object tracking) 외에도 영상 세그멘테이션(segmentation), 데이터 클러스터링(clustering), 경계를 보존하는 영상 스무딩(smoothing) 등 다양한 활용을 갖는다. 구체적 활용 예 및 보다 심도깊은 이론적 내용에 대해서는 "Mean shift: a robust approach toward feature space analysis", PAMI 2002년도 논문을 참조하기 바란다.
3. Mean Shift를 이용한 영상 이동체 추적
영상추적을 하는 사람들은 Mean Shift를 하나의 추적방법인 것처럼 생각하지만, Mean Shift는 하나의 일반적인 방법론적 도구일 뿐이다. 따라서, Mean Shift를 가지고 영상 추적을 하는 것은 사실은 별개의 얘기이다.
Mean Shift를 이용한 영상추적 방법은 사실 Comaniciu, Ramesh, Meer, "Real-time tracking of non-rigid objects using mean shift", CVPR 2000 논문에 있는 방법을 지칭한다 (저자들은 mean-shift에 대해 특허도 걸어 놓았다). 여기서 설명하고자 하는 mean shift 추적 방법도 기본적으로는 이 논문에 있는 방법이다.
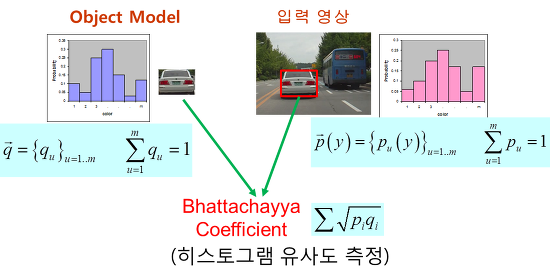
기본 아이디어는 아래 그림과 같이 추적하고자 하는 대상 물체에 대한 색상 히스토그램(histogram)과 현재 입력 영상의 히스토그램을 비교해서 가장 유사한 히스토그램을 갖는 윈도우 영역을 찾는 것이다.
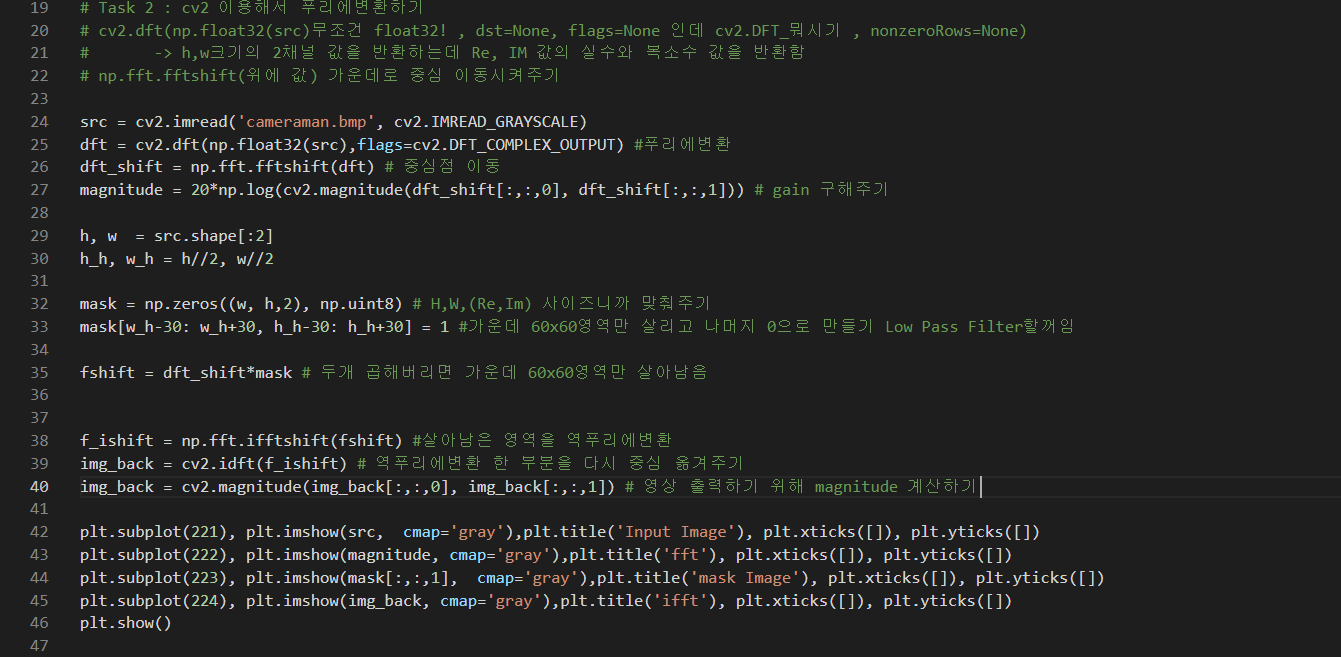
그런데 이렇게 직접 히스토그램을 비교할 경우에는 모든 가능한 윈도우 위치에 대해 각각 히스토그램을 구하고 또 비교해야 하기 때문에 시간이 너무 오래 걸린다.
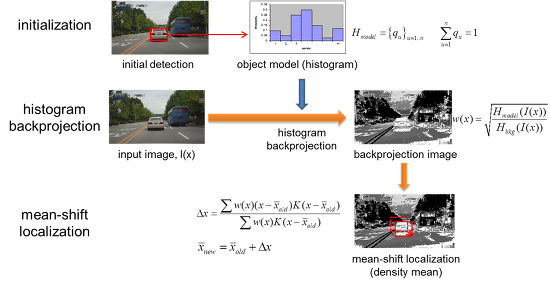
따라서 실제로는 아래 그림과 같이 histogram backprojection 기법과 mean shift를 결합한 방법을 사용하는 것이 일반적이다 (이렇게 해도 가장 유사한 히스토그램 영역을 찾을 수 있다는게 위 CVPR 2000 논문의 핵심 내용이며, 논문에 그 증명이 나와있다)
먼저, 영상에서 추적할 대상 영역이 정해지면 해당 윈도우 영역에 대해 히스토그램을 구하여 객체 모델로 저장한다. 이후 입력 영상이 들어오면 histogram backprojection을 이용해서 입력 영상의 픽셀값들을 확률값으로 변경시킨다. 이렇게 구한 확률값 분포에 대해 mean shift를 적용하여 물체의 위치를 찾는다. 만일 물체의 크기 변화까지 따라가고 싶은 경우에는 찾아진 위치에서 윈도우의 크기를 조절해 가면서 저장된 모델과 가장 히스토그램 유사도가 큰 스케일(scale)을 선택한다.
4. Mean Shift 추적 구현
[히스토그램 구하기]
색상 모델은 RGB, HSV, YCbCr 등 어느것을 써도 된다 (큰 차이가 없다). 또는 그레이(gray)를 사용하거나 HSV의 H(Hue)만 사용해도 된다. 히스토그램은 윈도우에 들어오는 픽셀들에 대해 각 색상별로 픽셀 개수를 센 다음에 확률적 해석을 위해 전체 픽셀수로 나눠주면 된다.
[히스토그램 백프로젝션(backprojection)]
현재 입력 영상에 있는 픽셀 색상값이 추적하고자 하는 객체 모델에 얼마나 많이 포함되어 있는 색인지를 수치화하는 과정이다. 모델 히스토그램을 Hm, 입력 이미지 I의 픽셀 x에서의 색상값을 I(x)라 하면 백프로젝션 값은 w(x) = Hm(I(x)) 와 같이 구할 수 있다. 그런데, 보통은 현재 입력 영상에 대한 히스토그램 H를 구한 후 w(x) = sqrt{Hm(I(x))/H(I(x))}와 같이 모델 히스토그램 값을 현재 영상 히스토그램 값으로 나누는 것이 일반적이다. 이렇게 값을 나누어 주면 모델에 포함된 색상값들이 그 비율에 관계없이 일정하게 높은 w값을 갖게 하는 효과가 있다. 예를 들어, 추적하고가 하는 물체가 빨간색 영역이 10%, 파란색 영역이 90%로 구성된 경우를 생각해 보기 바란다.
[Mean Shift 적용]
히스토그램 백프로젝션을 통해 얻은 w값들을 일종의 확률값처럼 생각하고 mean shift를 적용하는 것이다. 이전 영상 프레임(frame)에서의 물체의 위치를 초기 위치로 해서 다음과 같이 mean shift를 적용한다.
즉, w를 가중치(weight)로 해서 현재 윈도우(window)내에 있는 픽셀 좌표들의 가중평균(무게중심) 위치를 구하는 것이다. 이렇게 구한xnew가 새로운 윈도우의 중심이 되도록 윈도우를 이동시킨 다음에 수렴할 때까지 이 과정을 반복하는 것이다. 식에 있는 K(ri)에서 K는 커널(kernel) 함수, ri는 현재 윈도우 중심에서 xi까지의 거리를 나타낸다. 커널함수는 배경의 영향을 줄이기 위한 목적으로 사용하는데, 윈도우 중심에서 가장 높은 값을 갖고 중심에서 멀어질수록 값이 작아지는 방사형의 symmetric 함수가 주로 사용된다. 아무래도 윈도우의 경계 부근에서는 배경 픽셀이 포함될 확률이 높기 때문에 경계로 갈수록 가중치를 낮춰주는 것이다. 실제 커널 함수로는 Epanechnikov 함수가 주로 사용된다.
아니면 그냥 윈도우에 내접하는 타원에 대해 타원 내부에 있으면 1, 외부면 0인 함수를 커널로 사용해도 된다.
[히스토그램 유사도 측정]
두 히스토그램 H1 = {p1,...,pn}, H2 = {q1,...,qn} 사이의 유사도는 보통 Bhattacharyya 계수(coefficient)를 이용해서 계산한다.
Bhattacharyya 계수는 두 히스토그램이 일치할 때 최대값 1, 상관성이 하나도 없으면 최소값 0을 갖는다.
[물체의 크기(scale) 결정]
일단 mean shift로 위치를 찾은 다음에 윈도우의 크기를 조금씩 변경시켜 보면서 모델 히스토그램과 현재 윈도우 영역에 대한 히스토그램을 비교한다. Bhattacharyya 계수가 가장 큰 경우를 찾으면 된다.
5. Mean Shift 샘플 동영상
직접 구현한 Mean Shift 추적기를 실제 영상추적에 적용한 샘플 동영상이다. 녹색이 배경과 잘 구분되기 때문에 초반에는 비교적 잘 추적하지만 후반부에는 같은 팀 선수들 사이로 여기저기 옮겨다니는 걸 볼 수 있다.
Mean Shift 추적은 일단은 가장 기본적인 방법이기 때문에 영상 추적을 한다면 한번 정도는 직접 해 볼 필요가 있다. 하지만 성능은 그다지 기대하지 않는 것이 좋다. 추적하고자 하는 물체와 배경이 유사한 색상을 가지면 실패하기 쉽상이기 때문이다. 또한 물체의 크기가 변하는 경우도 큰 문제이다. Mean Shift 추적은 윈도우 크기가 잘못되면 성능이 형편없어진다.
그럼에도 불구하고 Mean Shift 추적은 대상의 형태가 변하는 경우에 유용하며, 가볍고 빠르기 때문에 나름 유용하다. 일반적인 실외환경이 아니라 제한된 환경 및 응용에서는 Mean Shift가 매우 강력한 방법이 될 수도 있다. 또는 Mean Shitf를 다른 추적 방법과 상호 보완적으로 결합하여 사용하는 것도 좋은 방법이 될 것이다.
아래 동영상은 유투브에서 발견한 것인데 mean shift가 성공적으로 적용되는 경우들을 보여준다. 후반부에 나오는 경찰 추격신이 꽤나 흥미롭다.
SIFT (Scale-Invariant Feature Transform)은 이미지의 크기와 회전에 불변하는 특징을 추출하는 알고리즘입니다. 서로 다른 두 이미지에서 SIFT 특징을 각각 추출한 다음에 서로 가장 비슷한 특징끼리 매칭해주면 두 이미지에서 대응되는 부분을 찾을 수 있다는 것이 기본 원리입니다. 즉, 그림 1과 같이 크기와 회전은 다르지만 일치하는 내용을 갖고 이미지에서 동일한 물체를 찾아서 매칭해줄 수 있는 알고리즘입니다.
그림 1. SIFT로 이미지 매칭한 예
위에 두 이미지에서 동일한 부분인 책을 찾아서 매칭해준 것을 확인할 수 있습니다. 중요한 것은 이미지의 크기도 다르고, 책의 회전? 방향도 다르고, 다른 물체들에 조금씩 가려져 있는데도 일치되는 부분을 잘 찾아서 매칭해주었습니다. 이것이 바로 SIFT의 장점입니다. SIFT는 크기나 회전에 불변하는 특징을 찾아내줍니다. 위의 이미지들은 흑백이라 조금 보기 안 이쁘니 다른 예를 하나 더 살펴보겠습니다. 그림 2와 그림 3을 보시죠 (참고로 이 사진은 부산에 아는 형 결혼식 갔다가 찍은 사진입니다.) 그림 2에서는 왼쪽 아래에 있는 빨간 색 차를 매칭해봤습니다. 차 사진이 회전되었고, 좀 더 흐려졌음에도 잘 매칭되었음을 확인할 수 있습니다.
그림 2. SIFT를 이용해서 두 이미지 안에 있는 빨간 색 차를 매칭
그림 3에서는 표지판을 매칭했는데, 두 포인트 정도 완전히 엇나간 것을 제외하고는 비교적 잘 매칭되었습니다.
그림 3. SIFT를 이용해서 두 이미지 안에 있는 표지판을 매칭
이런 식으로 작동하는 SIFT는 파노라마 영상을 만들 때도 사용됩니다. 파노라마 사진 만드는 알고리즘을 보진 않았지만 아마도 여러 장 조금 겹치게 찍은 사진에서 서로 겹치는 부분을 찾아서 옆에 붙이고 붙여주는 원리를 갖고 있지 않을까 싶네요. 그리고 SIFT는 두 장의 이미지가 좌우로 조금 다른 수평 디스패리티를 갖고 있는 스테레오 이미지를 매칭할 때도 사용될 수 있습니다.
그렇다면, 도대체 SIFT 알고리즘은 어떤 순서를 갖고 있기에 회전과 크기 변화에도 robust하게 서로 매칭되는 부분을 잘 찾아낼 수 있는 것일까요? 절차를 하나씩 잘 살펴보겠습니다. 대략적으로 아래와 같은 순서로 진행됩니다.
1. "Scale space"만들기
2. Difference of Gaussian (DoG) 연산
3. keypoint들 찾기
4. 나쁜 Keypoint들 제거하기
5. keypoint들에 방향 할당해주기
6. 최종적으로 SIFT 특징들 산출하기
자, 그러면 하나씩 살펴보도록 하겠습니다.
1. "Scale space" 만들기
첫번째로"Scale space"만들기입니다. Scale space에 대한 개념은 아래 링크를 참고하세요.(http://bskyvision.com/144) 먼저 원본 이미지를 두 배로 크게 만든 다음에 점진적으로 블러되게 만듭니다. 그리고 원본 이미지를 점진적으로 블러되게 만듭니다. 그 다음에는 원본 이미지를 반으로 축소시킨 이미지에서 또한 점진적으로 블러된 이미지들을 만들어냅니다. 그리고 또 반으로 축소시킨 다음에 점진적으로 블러된 이미지들을 만들어냅니다. (원본 이미지를 일단 2배로 키우는 이유는 나중에 Difference of Gaussian (DoG) 이미지를 만들 때 같은 옥타브 내에서 인접한 2개의 블러 이미지를 활용해서 만들고, 또 그렇게 생성된 DoG 이미지들 중에서 인접한 세 개의 DoG 이미지를 활용해서 Keypoint들을 찾기 때문입니다.) 그림 4에 구현한 결과를 나타냈습니다.
그림 4. Scale space 만든 결과
blurring, 즉 흐리게 만드는 것은 가우시안 연산자와 이미지를 컨볼루션 연산해줌으로 가능합니다. 공식으로 나타내면 아래와 같습니다.
...(1)
여기서 L은 블러된 이미지이고, G는 가우시안 필터이고, I는 이미지입니다. x, y는 이미지 픽셀의 좌표값이고,
는 "scale" 파라미터입니다. 이거 이름을 왜 scale 파라미터라고 했는지는 잘 모르겠지만, 아무튼 블러의 정도를 결정짓는 파라미터입니다. 값이 클수록 더 흐려집니다. 아래는 가우시안 필터의 공식입니다.
...(2)
점차적으로 블러된 이미지를 얻기 위해서
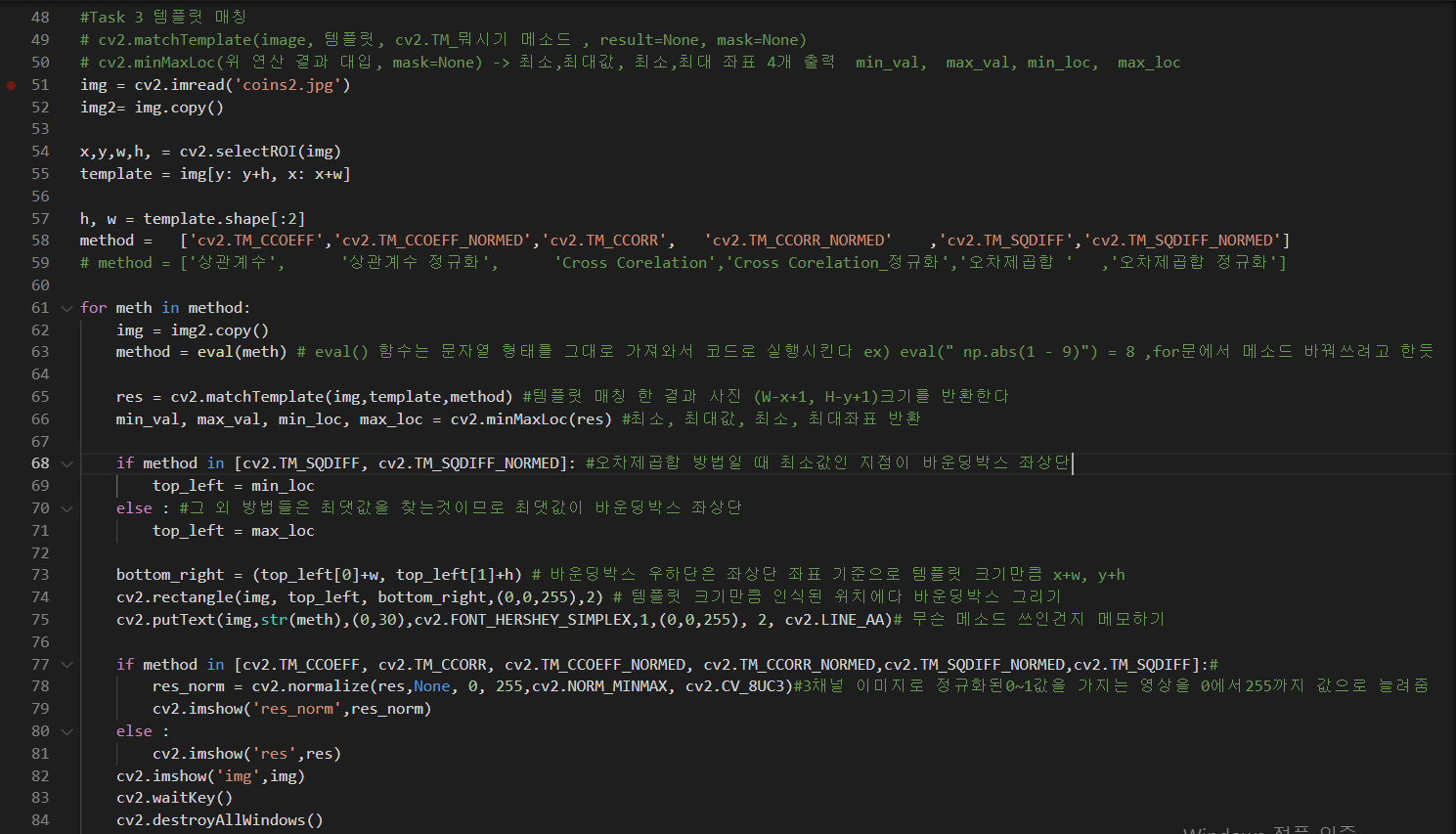
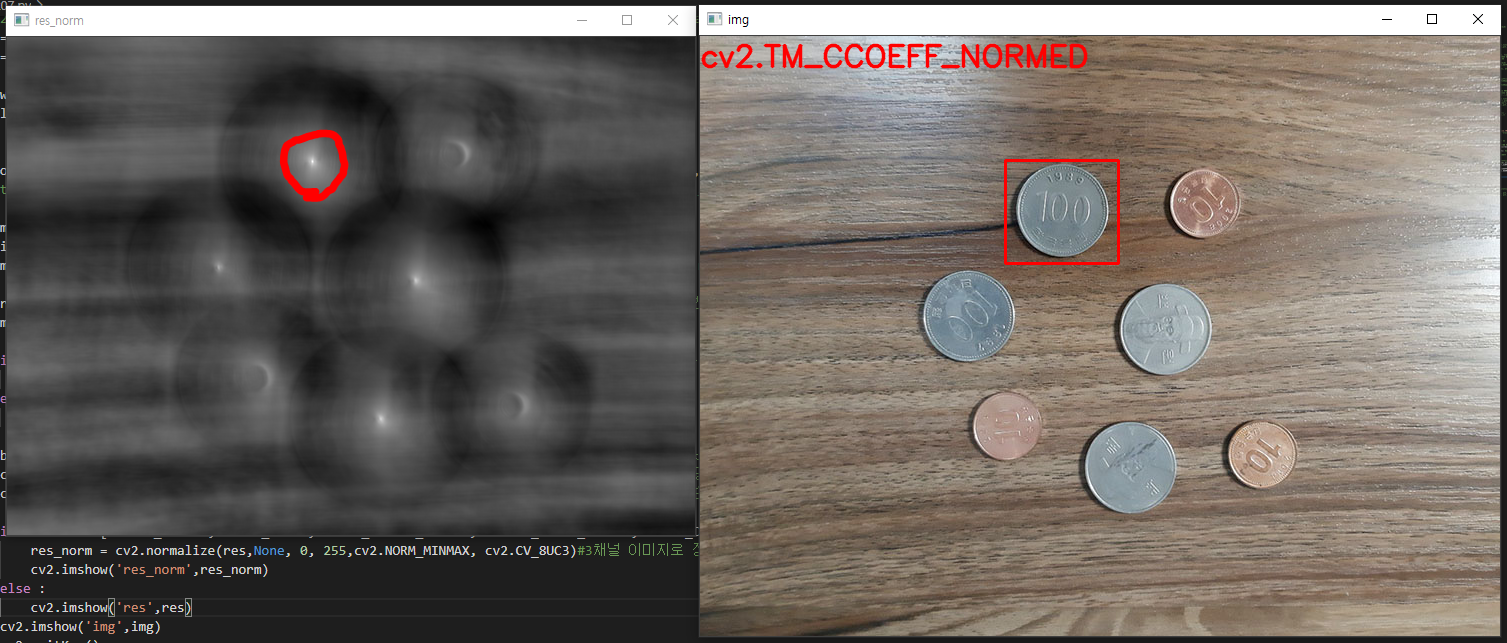
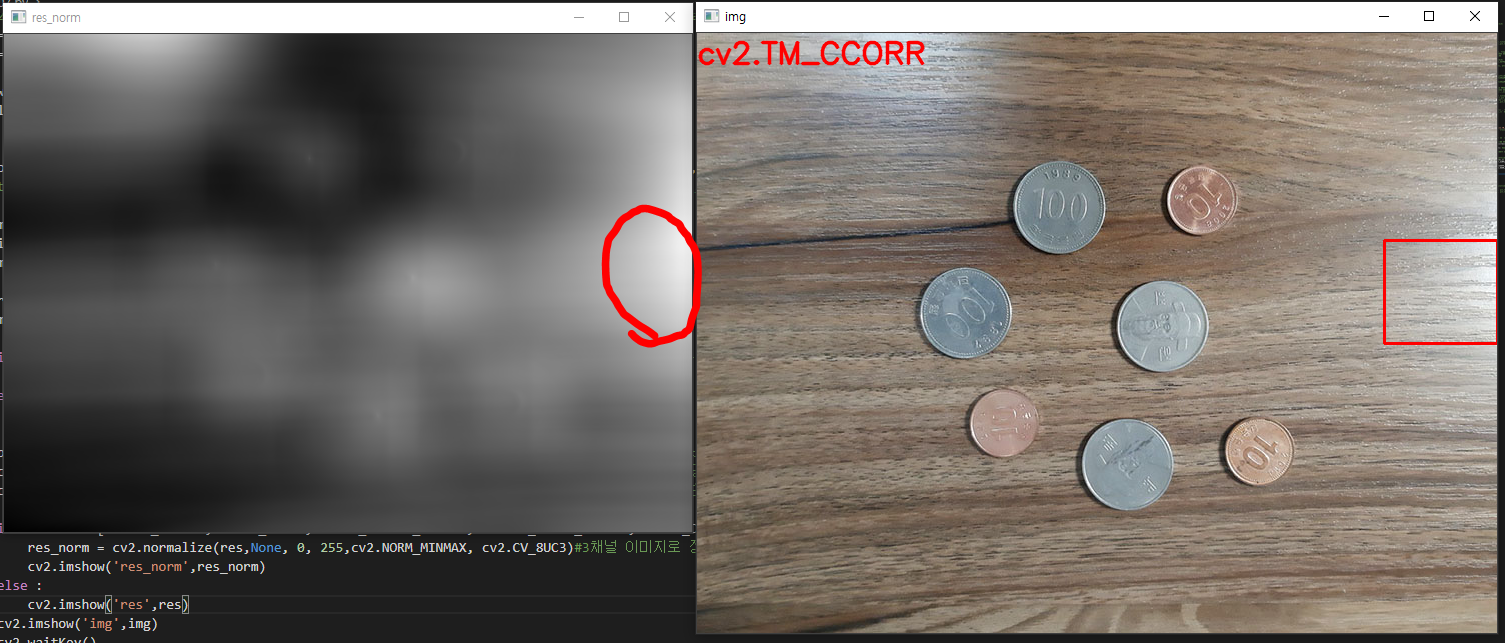
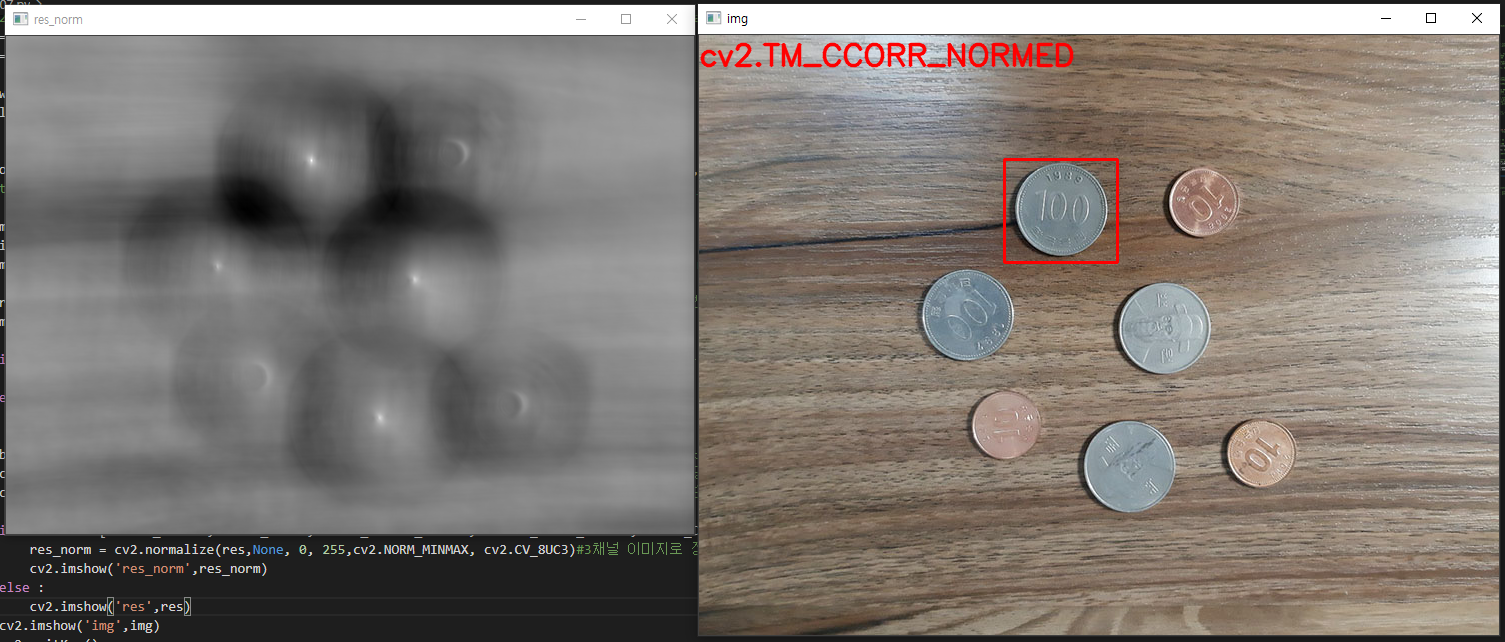
값을 k배씩 높여갔습니다. 처음
값을
으로, k 는
로 설정했습니다. 2배로 키운 원본이미지가 처음에는
의 값으로 블러되었다면, 그 다음에는 1이 되고, 그 다음에는
, 또 그 다음에는 2의 값으로 블러가 되는 방식입니다. 점점 더 흐려진 결과를 볼 수 있습니다. 원본 이미지에서는
에서 시작해서 k배씩 점차적으로 블러되게 해줍니다. 그리고 원본 이미지의 크기를 가로, 세로 각각 반씩 줄인 다음에는
에서 시작해서 k배씩 점차적으로 블러되게 해줍니다. 같은 사이즈를 갖지만 다른 블러의 정도를 갖는 이미지가 각각 5장씩 존재하고, 총 4개의 그룹을 형성하게 됩니다. 여기서 같은 사이즈의 이미지들의 그룹을 octave라고 명칭합니다. 즉, 세로로 배열되어 있는 이미지들이 한 옥타브를 형성합니다. 아마도 우리가 어떤 물체를 볼 때 거리에 따라 명확하거나 흐리게 보이기도 하고, 크거나 작게 보이기도 하는 현상을 담으려고 이런 방법을 쓰는 것이 아닐까 싶습니다. 이 과정 덕분에 SIFT 특징은 이미지의 크기에 불변하는 특성을 갖게 됩니다.
2. DoG 연산
전 단계에서 저희는 이미지의 scale space를 만들었습니다. 다양한 scale값으로 Gaussian 연산처리된 4 그룹의 옥타브, 총 20장의 이미지를 얻었습니다. 이제 Laplacian of Gaussian (LoG)를 사용하면 이미지 내에서 흥미로운 점들, 즉 keypoint들을 찾을 수 있습니다. LoG 연산자의 작동 원리를 간단히 말하자면, 먼저 이미지를 살짝 블러한 다음에 2차 미분을 계산합니다. 식으로 나타내면 다음과 같습니다.
...(3)
LoG 연산을 통해서 이미지 내에 있는 엣지들과 코너들이 두드러지게 됩니다. 이러한 엣지들과 코너들은 keypoint들을 찾는데 큰 도움을 줍니다. 하지만 LoG는 많은 연산을 요구하기 때문에, 비교적 간단하면서도 비슷한 성능을 낼 수 있는Difference of Gaussian (DoG)로 대체합니다. LoG, DoG 모두 이미지에서 엣지 정보, 코너 정보를 도출할 때 널리 사용되는 방법들입니다. DoG는 매우 간단합니다. 전 단계에서 얻은 같은 옥타브 내에서 인접한 두 개의 블러 이미지들끼리 빼주면 됩니다. 그림 5는 그 과정을 설명해줍니다.
그림 5. SIFT 내에서의 DoG 연산 [2]
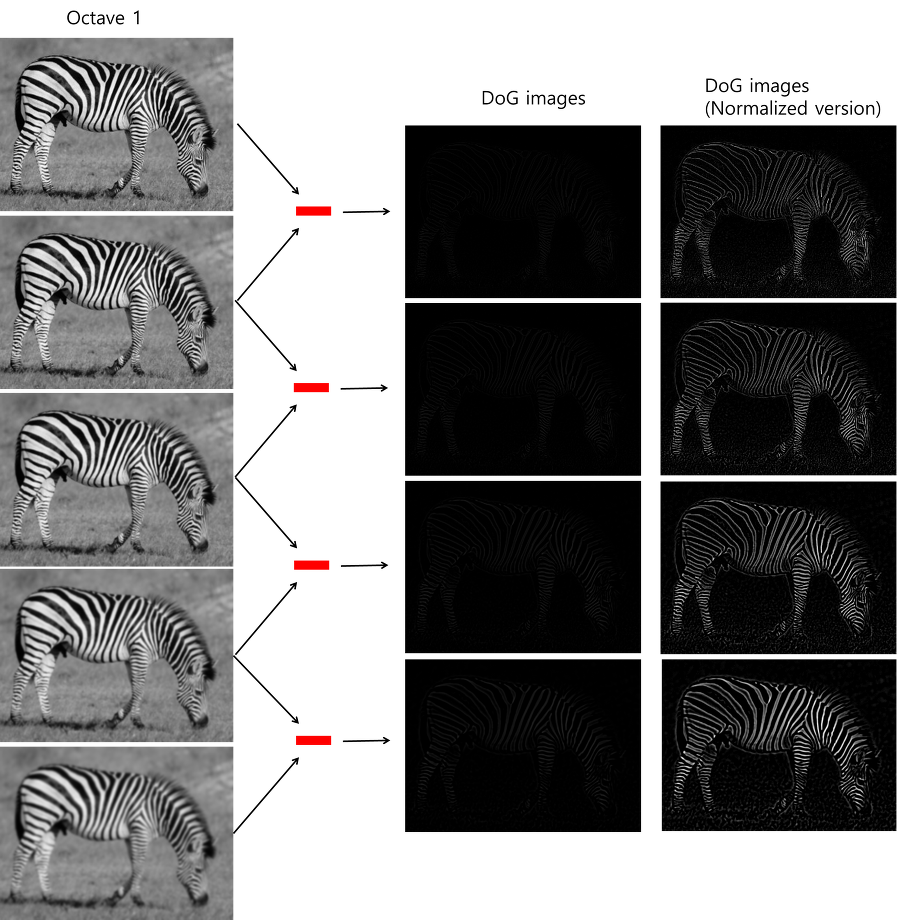
이 과정을 실제 이미지로 구현한 결과는 그림 6에 있습니다.
그림 6. DoG 연산을 실제로 구현한 결과
중간에 있는 DoG 이미지들 그냥 검은색 이미지 아닙니다. 컴퓨터 화면이 얼룩진건가 하시는 분들도 있을 텐데 자세히 봐보세요. 얼룩말의 형상이 보일 것입니다. 그래도 잘 안보이는 것 같아서, 정규화한 버전의 DoG 이미지들도 오른쪽에 추가했습니다. 이미지의 엣지 정보들이 잘 도출된 것을 확인할 수 있습니다. 이 과정이 모든 octave에서 동일하게 진행됩니다. 그러면 결과적으로 4개씩, 16장의 DoG이미지를 얻겠죠??
여기서 잠깐 LoG와 DoG에 대해 좀 더 깊이 살펴보고 지나가겠습니다. LoG를 DoG로 대체할 때 시간이 적게 걸린다는 것 외에도 장점이 더 있습니다. LoG는 scale 불변성을 위해
로 라플라시안 연산자를 정규화(normalization)해줘야합니다. 즉, LoG연산자가 아래와 같이 scale-normalized LoG로 변합니다.
...(4)
scale-normalized LoG의 극대값, 극소값은 매우 안정적으로 이미지 특징을 나타냅니다. 그래서 이 극대값, 극소값들은 keypoint의 후보가 되는 것입니다. 그러면 도대체 어떻게 LoG가 DoG로 대체될 수 있을까요? 이것을 증명하기 위해서 열 확산 방정식이 응용됩니다.
...(5)
열 확산 방정식에 의해 이런 관계가 형성된다고 합니다. Gaussian을
에 대해 미분한 것은 LoG에
를 곱한 것과 같다는 의미죠. 이것은 미분함수의 성질을 이용하면 다음과 같이 전개될 수 있습니다.
...(6)
양변에 우변의 분모를 각각 곱해주면, 아래와 같은 식이 나오게 되죠.
...(7)
결국 다른 scale을 갖고 있는 Gaussian 이미지들끼리의 합, 즉 DoG는 scale-normalized LoG에 (k-1)을 곱한 것과 거의 같습니다. 따라서 DoG는 scale 불변성을 보장하는
scale 정규화 과정을 자연스럽게 포함하게 됩니다. 그리고 곱해진 (k-1)은 극대값, 극소값을 찾는데는 아무런 영향을 주지 않기 때문에 무시해도 괜찮습니다. 암튼 이러한 방식으로 LoG는 DoG로 무리없이 잘 대체됩니다. (오히려 상당부분 이득을 보면서 대체됩니다.)
이제 이 DoG 이미지들을 활용해서 흥미있는 keypoint들을 찾아낼 것입니다.
3. keypoint들 찾기
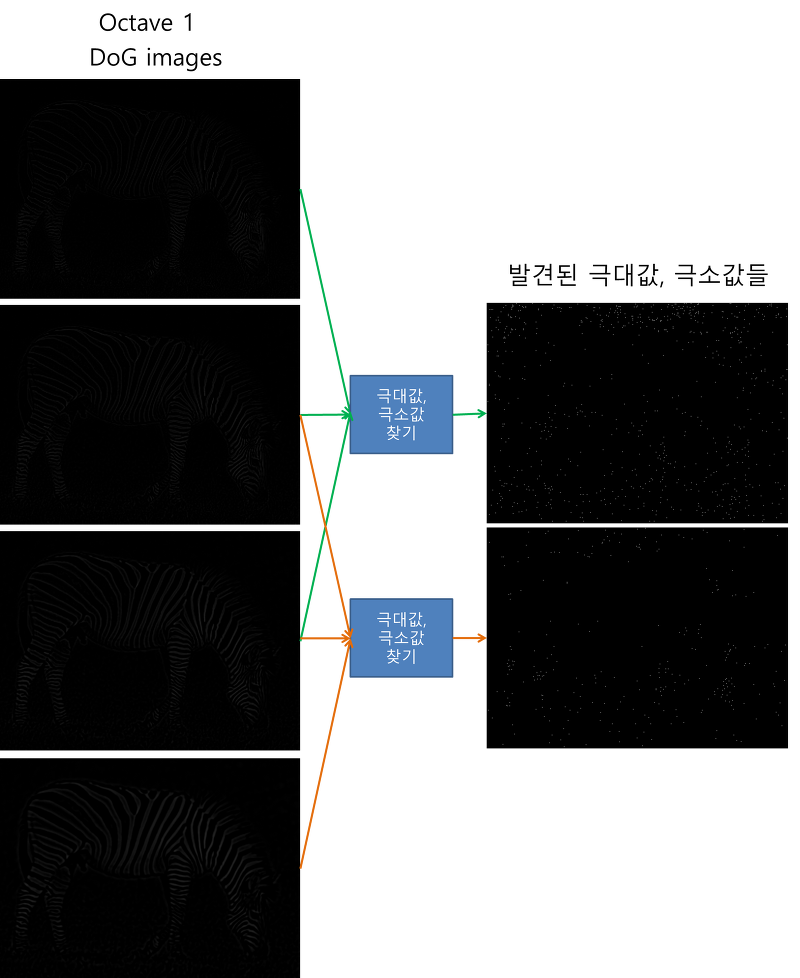
이제 DoG 이미지들에서 keypoint들을 찾을 차례입니다. 먼저 DoG 이미지들 내에서 극대값, 극소값들의 대략적인 위치를 찾습니다. 그림 7에 극대값, 극소값의 위치를 찾는 방법이 설명되어 있습니다.
그림 7. DoG이미지에서 극소값, 극대값 찾는 원리
한 픽셀에서의 극대값, 극소값을 결정할 때는 동일한 octave내의 세 장의 DoG 이미지가 필요합니다. 체크할 DoG이미지와 scale이 한 단계씩 크고 작은 DoG 이미지들이 필요합니다. 지금 체크할 픽셀 주변의 8개 픽셀과, scale이 한단계씩 다른 위 아래 두 DoG 이미지에서 체크하려고 하는 픽셀과 가까운 9개씩, 총 26개를 검사합니다. 만약 지금 체크하는 픽셀의 값이 26개의 이웃 픽셀값 중에 가장 작거나 가장 클 때 keypoint로 인정이 됩니다. 그러므로 4장의 DoG 이미지들 중에서 가장 위에 있고 가장 아래에 있는 DoG 이미지들에서는 극대값, 극소값을 찾을 수 없습니다. 이런 방식으로 DoG 이미지의 모든 픽셀에서 Keypoint들을 찾습니다. 좀 더 확실한 이해를 위해 이 과정을 실제 이미지로 구현해보겠습니다. 이번에도 octave1에서의 결과만 보이도록 하겠습니다. 그림 8을 확인하세요. 나머지 octave들에서도 동일한 연산이 이루어진다는 것을 잊지 마세요.
그림 8. 극대값, 극소값 찾기
흰색 점들로 표현된 곳이 극대값, 극소값들입니다. 역시 잘 안보이지만 모니터의 각도를 좀 바꿔보면 잘 보이는 각도가 있을거에요. 암튼 이 점들이 일차적으로 keypoint들이 됩니다. 여기서 보면 두 장의 극값 이미지를 얻기 위해서는 4장의 DoG이미지가 필요하다는 것을 알 수 있습니다. 이를 위해서 scale space를 만들 때 5 단계의 가우시안 블러 이미지를 만든 것입니다. 5장의 블러 이미지에서 4장의 DoG 이미지가 나오고, 또 4장의 DoG 이미지에서 2장의 극값 이미지가 나오는 거죠. 네 그룹의 octave를 갖고 있으니, 8장의 극값 이미지를 얻게 됩니다. 그런데, 이렇게 얻은 극값들은 대략적인 것입니다. 왜냐하면, 그림 9에 설명한 것과 같이 진짜 극소값, 극대값들은 픽셀들 사이의 공간에 위치할 가능성이 많기 때문이죠.
그림 9. 진짜 극값의 위치
그런데 우리는 이 진짜 극소값, 극대값들의 위치에 접근할 수 없습니다. 그래서 subpixel 위치를 수학적으로 찾아내야 합니다. subpixel은 이렇게 픽셀들 사이에 위치한 것을 의미하는 것 같습니다. 좀 더 정확한 극값들을 어떻게 찾아내는가 하면, 바로 테일러 2차 전개를 사용합니다. (여기 테일러 전개에 대한 이론적인 내용은 저도 잘 모르겠네요. 일단 대략적인 개념만 이해하고 넘어가셔도 좋습니다.)
...(8)
여기서 D는 DoG이미지이고, x는
입니다. 이걸 x로 미분해서 0이 되게 하는 x의 값, 즉
이 극값의 위치가 됩니다. 계산하면 아래와 같이 구해진다고 합니다.
...(9)
이 과정은 알고리즘이 좀 더 안정적인 성능을 낼 수 있게 도와줍니다.
4.나쁜 Keypoint들 제거하기
이제 전 단계에서 극값들로 찾은 keypoint들 중에서 활용가치가 떨어지는 것들은 제거해줘야 합니다. 두 가지 기준으로 제거해주는데요, 첫번째는 낮은 콘트라스트를 갖고 있는 것들을 제거해줍니다. 그 다음 엣지 위에 존재하는 것들을 제거해줍니다.
먼저 낮은 콘트라스트의 keypoint들을 제거해주는 과정을 살펴보겠습니다. 간단히 DoG 이미지에서 keypoint들의 픽셀의 값이 특정 값(threshold)보다 작으면 제거해줍니다. 저희는 지금 subpixel 위치에서 keypoint들을 갖고 있기 때문에 이번에도 역시 테일러 전개를 활용해서 subpixel 위치에서의 픽셀값을 구합니다. 간단히 위에서 구한
을 (8)에 대입해주면 됩니다. 그 결과는 (10)과 같습니다.
...(10)
이 값의 절대값이 특정 값보다 작으면 그 위치는 keypoint에서 제외됩니다.
이제 두번째로 엣지 위에 존재하는 keypoint들을 제거해줍니다. 그 이유를 저는 다음과 같이 이해했습니다. DoG가 엣지를 찾아낼 때 매우 민감하게 찾아내기 때문에, 약간의 노이즈에도 반응할 수 있는 위험이 있습니다. 즉, 노이즈를 엣지로 찾아낼 수도 있다는 것입니다. 그래서 엣지 위에 있는 극값들을 keypoint로 사용하기에는 조금 위험성이 따릅니다. 따라서 좀 더 확실하고 안전한 코너점들만 keypoint로 남겨주는 것이죠. 이를 위해서 keypoint에서 수직, 수평 그레디언트를 계산해줍니다. 수평 방향으로는 픽셀 값이 어떻게 변화하는지, 수직 방향으로는 픽셀 값이 어떻게 변화하는지 변화량을 계산하는 것입니다. 만약 양 방향으로 변화가 거의 없다면 평탄한 지역(flat region)이라고 생각할 수 있습니다. 근데 수직 방향(or 수평 방향)으로는 변화가 큰데, 수평 방향(or 수직 방향)으로는 변화가 적으면 엣지(가장자리)라고 판단할 수 있습니다. 또 수직, 수평 방향 모두 변화가 크면 코너(모서리)라고 판단할 수 있구요. 설명이 부족하다면, 아래 그림10을 보세요.
그림 10. flat 지역, 엣지, 코너 설명
이 중에서 코너들이 좋은 keypoint들입니다. 따라서 우리의 목적은 코너에 위치한 keypoint들만 남기는 것입니다. Hessian Matrix를 활용하면 코너인지 아닌지 판별할 수 있다고 합니다. 이 두 제거 과정을 통해 그림 11에서 확인할 수 있듯이 keypoint의 갯수는 상당히 줄어듭니다. 흰 점들이 상당히 많이 줄어들었죠.
그림 11. 나쁜 keypoint들 제거한 결과
이제는 이 keypoint들에게 방향을 할당해줄 차례입니다.
5.keypoint들에 방향 할당해주기
전 단계에서 우리는 적당한 keypoint들을 찾았습니다. 이 keypoint들은 scale invariance(스케일 불변성)를 만족시킵니다. 이제는 keypoint들에 방향을 할당해줘서 rotation invariance(회전 불변성)를 갖게 하려고 합니다. 방법은 각 keypoint 주변의 그레디언트 방향과 크기를 모으는 것입니다. 그런 다음 가장 두드러지는 방향을 찾아내어 keypoint의 방향으로 할당해줍니다. 그림 12와 같이 하나의 keypoint 주변에 윈도우를 만들어준 다음 가우시안 블러링을 해줍니다. 이 keypoint의 scale값(블러의 정도를 결정해주는 파라미터)으로 가우시안 블러링을 해줍니다.
그림 12. keypoint 주변에서 그레디언트 크기와 방향에 대한 값들 모으기위해 윈도우 설정 [1]
그 다음에 그 안에 있는 모든 픽셀들의 그레디언트 방향과 크기를 다음의 공식들을 이용해서 구합니다.
...(11)
그 결과는 그림 13과 같습니다.
그림 13. 그레디언트 크기, 방향 계산 결과 [3]
여기서 그레디언트 크기에는 가우시안 가중함수를 이용해서 keypoint에 가까울수록 좀 더 큰 값을, 멀수록 좀 더 작은 값을 갖게 해줍니다. 이 과정은 그림 14에 있습니다.
그림 14. 그레디언트 크기에 가우시안 가중함수를 곱해준 결과 [3]
이제 각 keypoint에 어떻게 방향을 할당해주는지 살펴보도록 하겠습니다. 먼저 36개의 bin을 가진 히스토그램을 만듭니다. 360도의 방향을 0~9도, 10~19도, ... , 350~359도로 10도씩 36개로 쪼갭니다. 그래서 만약 28도면 3번째 bin을 그레디언트 크기만큼 채우는 것입니다. 여기서 그레디언트 크기는 가중처리된 값입니다. 윈도우 내의 모든 픽셀에서 그레디언트 방향의 값을 이런 식으로 해당하는 bin에 채워줍니다. 그러면 그레디언트 방향에 대한 히스토그램이 완성됩니다. 그림 15를 보시죠.
그림 15. keypoint 주변 그레디언트 방향 히스토그램 [1]
이런 히스토그램이 만들어집니다. 가장 높은 bin의 방향이 keypoint의 방향으로 할당됩니다. 또 여기서 만약 가장 높은 bin의 80% 이상의 높이를 갖는 bin이 있다면 그 방향도 keypoint의 방향으로 인정됩니다. 한 keypoint가 두 개의 keypoint로 분리되는 것입니다. 마찬가지로 만약 3개의 bin이 가장 높은 bin의 80% 이상의 높이를 갖는다면 총 4개의 keypoint로 분리됩니다. 이제 keypoint들에 방향을 할당해주는 작업이 완료되었습니다.
6. 최종적으로 SIFT 특징들 산출하기
지금까지 keypoint들을 결정해왔습니다. 우리는 지금 keypoint들의 위치와 스케일과 방향을 알고 있습니다. 그리고 keypoint들은 스케일과 회전 불변성을 갖고 있습니다. 이제 이 keypoint들을 식별하기 위해 지문(fingerprint)과 같은 특별한 정보를 각각 부여해줘야 합니다. 각각의 keypoint의 특징을 128개의 숫자로 표현을 합니다. 이를 위해 keypoint 주변의 모양변화에 대한 경향을 파악합니다. keypoint 주변에 16x16 윈도우를 세팅하는데, 이 윈도우는 작은 16개의 4x4 윈도우로 구성됩니다. 그림 16을 확인하세요.
그림 16. 하나의 keypoint의 특징을 나타내는 128개의 숫자를 얻는 과정
16개의 작은 윈도우에 속한 픽셀들의 그레디언트 크기와 방향을 계산해줍니다. 전 단계에서 했던 것과 비슷하게 히스토그램을 만들어주는데, 이번에는 bin을 8개만 세팅합니다. 360도를 8개로 쪼갤 것입니다. 0~44, 45~89, 90~134, ... , 320~359로 나눠지겠죠? 역시 그레디언트 방향와 크기를 이용해서 bin들을 채웁니다. 결국 16개의 작은 윈도우들 모두 자신만의 히스토그램을 갖게 됩니다. 16개의 작은 윈도우마다 8개의 bin값들이 있으므로, 16 x 8을 해주면 128개의 숫자(feature vector)를 얻게 됩니다. 이것이 바로 keypoint의 지문이 되는 것입니다. 아직 회전 의존성과 밝기 의존성을 해결해야합니다. 128개의 숫자로 구성된 feature vector는 이미지가 회전하면 모든 그레디언트 방향은 변해버립니다. 회전 의존문제를 해결하기 위해 keypoint의 방향을 각각의 그레디언트 방향에서 빼줍니다. 그러면 각각의 그레디언트 방향은 keypoint의 방향에 상대적이게 됩니다. (예를 들어 keypoint의 방향을 구한 것이 20-29도라면 24.5도를 keypoint 주변 16개의 4x4 윈도우의 방향에서 빼주면, 16개의 윈도우의 방향은 keypoint 방향에 상대적이게 됩니다.) 그리고 밝기 의존성을 해결해주기 위해서 정규화를 해줍니다. 이렇게 최종적으로 keypoint들에게 지문(fingerprint)을 할당해줬습니다. 이것이 바로 SIFT 특징입니다.
그렇다면 SIFT로 이미지 매칭을 어떻게 하는 것일까요? 먼저 두 이미지에서 각각 keypoint들을 찾고 지문을 달아줬다면, 이 지문값들의 차이가 가장 작은 곳이 서로 매칭되는 위치인 것입니다.
1994년도 후반, J. Shi and C. Tomasi 는 그들의 논문에서Good Features to Track라는 작은 수정을 했는데 이는 Harris Corner Detector에 비해서 더 좋은 성능을 나타내었다.
Harris Corner Detector 의 scoring function 은 다음과 같다.:
대신, Shi-Tomasi 가 제한한 함수는:
인데, 이것이 만약 threshold value 보다 크다면, 이를 코너라고 생각하는 것이다. 만약 우리가 이를
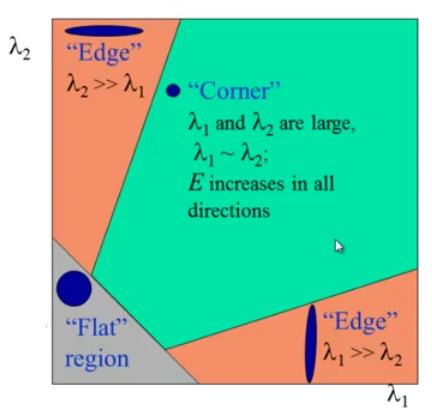
라는 공간 아래에 그린다면, Harris Corner Detector에서 보았던 공간 그림과 같을 것이다. 우리는 아래와 같은 이미지를 얻는다.
이 그림에서 당신은, λ1 과 λ2가 최소값 λmin 위일때만 , corner 라고 고려하면 된다. (green region).
Code
이 모든 정보를 통해 함수는 이미지의 코너를 찾는다. 품질 수준 이하의 모든 코너가 제외된다. 그런 다음 품질에 따라 내림차순으로 나머지 모서리를 정렬한다. 그런 다음 함수는 가장 강한 모서리를 가져 와서 최소 거리의 범위보다 가까운 모든 모서리를 버리고 N 개의 가장 강한 모서리를 반환한다.
이 함수는 Tracking에 더 적절하다고 하신다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('blox.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# (img, max number of corners, Quality level, Min Euclidian distance between corners)
corners = cv2.goodFeaturesToTrack(gray,25,0.01,10)
# img = float32 형식 그레이스케일 이미지
# max# = 검출할 최대 코너 수
# Quality = 품질 수준
# Min distance = 감지된 코너 사이의 최소 유클리드 거리
corners = np.int0(corners) #정수형으로 바꿔준다
for i in corners:
print('i:',i)
x,y = i.ravel() # 2D -> 1D로 바꿔준다
print('x:{}, y:{}'.format(x,y))
cv2.circle(img,(x,y),3,255,-1)
plt.imshow(img),plt.show()
- C, D는 빌딩의 엣지들이고 비슷한 위치를 찾을 수 있지만 정확한 위치는 추출하기 어렵다.
- E, F 는 어떤 빌딩의 코너다 이 코너는 찾기가 매우 쉽다
-----> 그래서 앞으로 코너를 검출함으로써 특징을 탐지하고 추적하는 것을 공부 할 예정.
- 어떻게 코너를 찾을 것인가?
-----> 직관적인 방법으로는 짧은 거리에서 최대한의 변화를 가진 이미지의 영역을 찾는다, 이를 Feature Detection이라고 한다
2) Harris Corner Detection
2-1) cv2.cornerHarris (img, blockSize, ksize, k)
img - 입력 이미지이고, 흑백스케일에 float32형태여야한다.
blockSize - 모서리 탐지를 위한 고려될 이웃 픽셀의 크기를 말한다.
ksize - 미분에 사용될 커널 사이즈
k - 방정식에서 나온 검출식에서의 k
모서리가 모든 방향의 Variation 의 강도가 큰 이미지의 영역이다.
먼저 , 기본적으로(u,v) 변위(위치변화)에 대한 강도의 변화를 찾는다.
모든방향에 대해서 이는 아래와 같이 표현될 수 있다.
위 식은 테일러급수 확장에 의해 아래 식이 된다.
위와 같은 식을 행렬곱으로 나타낸다면, 아래 식이 된다
위 식을 다시 정리하면 M은 아래 식과 같은데 Ix, Iy는 이미지의 x, y 방향으로의 미분값인데 sobel()필터 를 써서 쉽게 구할 수 있다.
최종적으로 얻어온 위치변화에 대한 강도 변화값은 다음과 같다
이렇게 얻어진 식을 가지고 이미지가 코너를 포함하고 있는지 아닌지에 대해 결정한다
(람다값은 행렬의 고유값을 나타낸다.)
- |R| 값이 작을경우 λ1, λ2 값이 둘 모두 작으므로 해당 영역은 평면이다.
- |R|<0 일 경우 λ1또는 λ2값 둘 중 하나가 압도적으로 큼으로 해당 영역은 edge다.
- |R|값이 매우 클 때 λ1, λ2 값 둘 모두 크다는 의미 이므로 λ1~ λ2 영역은 코너다!
import numpy as np
import cv2
img = cv2.imread('checkerboard.jpg')
# img = cv2.imread('blox.jpg')
#cornerHarris()에 들어갈 입력 이미지는 GrayScale에 float32형태여야 한다.
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray,2,3,0.04) #입력 영상,
# img - 입력 이미지이고, 흑백스케일에 float32형태여야한다.
# blockSize - 모서리 탐지를 위한 고려될 이웃 픽셀의 크기를 말한다.
# ksize - 미분에 사용될 커널 사이즈
# k - 방정식에서 나온 검출식에서의 k
#result is dilated for marking the corners, not important
dst = cv2.dilate(dst,None)
# Threshold for an optimal value, it may vary depending on the image.
img[dst>0.01*dst.max()]=[0,0,255] #이미지에서 dst값이 최대 dst픽셀값 x 0.01보다 큰 부분은 빨간색으로 칠한다.
cv2.imshow('dst',img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()